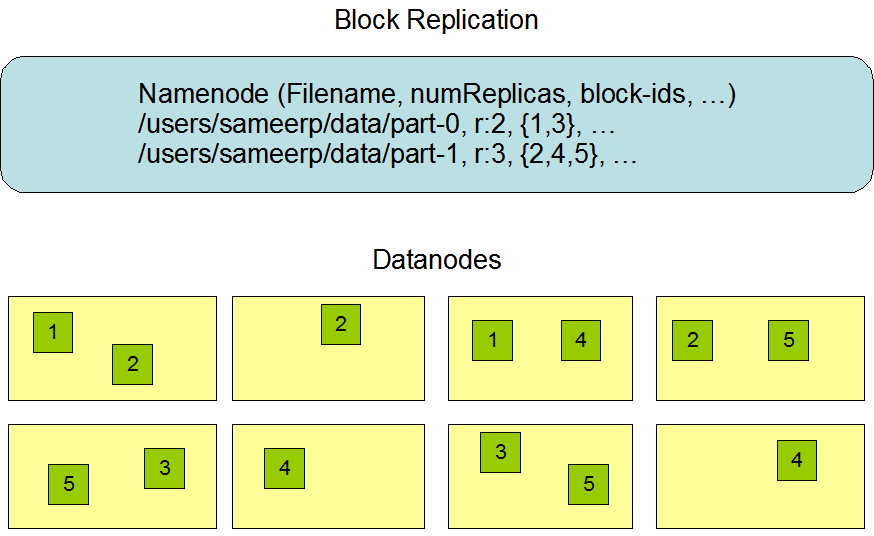
This document is an informal guide to setting up a test cluster on Amazon AWS, specifically the EC2 service. This is not a best practice guide nor is it suitable for a full PoC or production install of HDP.
Please refer to Hortonworks documentation online to get a complete set of documentation.
Create Instances
Created the following RHEL 6.3 64bit instances:
- m1.medium ambarimaster
- m1.large hdpmaster1
- m1.large hdpmaster2
- m1.medium hdpslave1
- m1.medium hdpslave2
- m1.medium hdpslave3
Note: when instantiating instances, I increased the root partition to 100Gb on each of them. For long term use, you may want to create separate volumes for your each of the datanodes to store larger amounts of data. Typical raw storage per node is 12-24Tb per slave node.
Note: I edit the Name column in the EC2 Instances screen to the names mentioned above so I know which box I’m dealing with
Configure Security Groups
Used the following security group rules:
| ICMP |
| Port (Service) |
Source |
Action |
| ALL |
sg-79c54511 (hadoop) |
Delete |
| TCP |
| Port (Service) |
Source |
Action |
| 0 – 65535 |
sg-79c54511 (hadoop) |
Delete |
| 22 (SSH) |
0.0.0.0/0 |
Delete |
| 80 (HTTP) |
0.0.0.0/0 |
Delete |
| 7180 |
0.0.0.0/0 |
Delete |
| 8080 (HTTP*) |
0.0.0.0/0 |
Delete |
| 50000 – 50100 |
0.0.0.0/0 |
Delete |
| UDP |
| Port (Service) |
Source |
Action |
| 0 – 65535 |
sg-79c54511 (hadoop) |
Delete |
Configure Nodes
On each and every node (using root):
vim /etc/sysconfig/selinux (set SELINUX=disabled)
vim /etc/sysconfig/network (set HOSTNAME=<chosen_name>.hdp.hadoop where <chosen_name> is one of the following: ambarimaster, hdpmaster1, hdpmaster2, hdpslave1, hdpslave2, hdpslave3 – depending on what EC2 instance you are on)
chkconfig iptables off
chkconfig ip6tables off
shutdown -r now #(only after the commands above are completed)
Note: when I do a restart of the node in this manner, my external EC2 names did NOT change. They will change if you actually halt the instance. This is separate concern from the internal IP addresses which we will get to further on in these instructions
Note: SSH on the RHEL instances has a time out. If your session hangs just give it a few seconds and you will get a “Write failed: Broken pipe” message; just reconnect the box and everything will be fine. Change the SSH timeout if you desire.
Key Exchange
Logged onto the ambarimaster ONLY: ssh-keygen -t rsa
On your local box (assuming a linux/mac laptop/workstation, if not use Cygwin, WinSCP, FileZilla, etc to accomplish the equivalent secure copy):
scp -i amuisekey.pem root@ec2-54-234-94-128.compute-1.amazonaws.com:/root/.ssh/id_rsa.pub ./
scp -i amuisekey.pem root@ec2-54-234-94-128.compute-1.amazonaws.com:/root/.ssh/id_rsa ./
Once you have your public and private key on your local box, you can distribute the public key to each node. Do this for every host except for the ambarimaster:
scp -i amuisekey.pem ./id_rsa.pub root@ec2-174-129-186-149.compute-1.amazonaws.com:/root/.ssh/
Log on to each host copy the public key for ambarimaster into each server’s authorized_key file:
cat id_rsa.pub >> authorized_keys
To confirm the passwordless ssh is working:
- Pick a host other than ambarimaster and determine the internal IP and keep it handy: ifconfig -a
- Log on to your ambarimaster and test passwordless ssh using the IP of the host you had just looked up: ssh root@10.110.35.23
- Confirm that you did actually land on the right host by checking the name: hostname
- Make sure you exit out of your remote session to your child node from the ambarimaster or things could get confusing very fast
Setup Hosts
Log on to the ambarimaster and edit the hosts:
- On each host, check the internal ip with: ifconfig -a
- Edit the hosts file on your ambarimaster: vim /etc/hosts
- Edit the hosts file to look the one below, taking into account your own IP addresses for each host:
127.0.0.1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
10.110.35.23 hdpmaster1.hdp.hadoop hdpmaster1
10.191.45.41 hdpmaster2.hdp.hadoop hdpmaster2
10.151.94.30 hdpslave1.hdp.hadoop hdpslave1
10.151.87.239 hdpslave2.hdp.hadoop hdpslave2
10.70.78.233 hdpslave3.hdp.hadoop hdpslave3
10.151.22.30 ambarimaster.hdp.hadoop ambarimaster
Note: the /etc/hosts is the file you will need to change if you shut down your EC2 instance and get a new internal IP. When you update this file you must make sure that all nodes have the same copy.
YUM Install
On the ambarimaster only, install the HDP yum repository:
cd
wget http://public-repo-1.hortonworks.com/ambari/centos6/1.x/GA/ambari.repo
cp ambari.repo /etc/yum.repos.d
yum install epel-release
yum repolist
Install and initialize the ambari server:
yum install ambari-server
ambari-server setup
ambari-server start
Now you can logon to Ambari. Make a note of the external hostname of your ambarimaster EC instance in the AWS console and go to: http://:8080 using your local host’s favorite web browser
Log on to Ambari with admin/admin
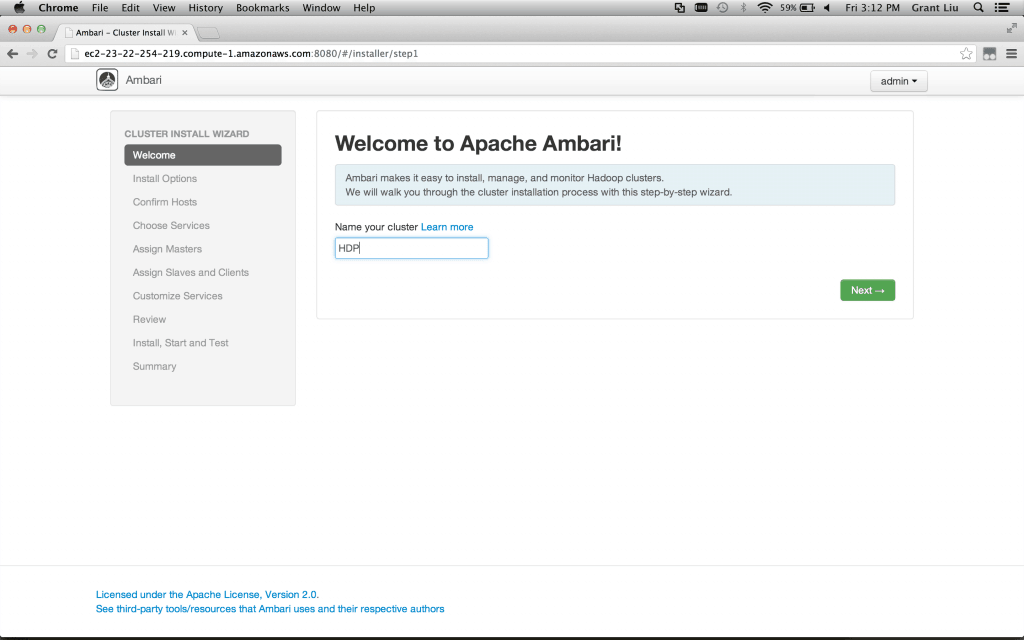
Using Ambari to Install
Going through the Ambari cluster install process:
Name your cluster whatever you want
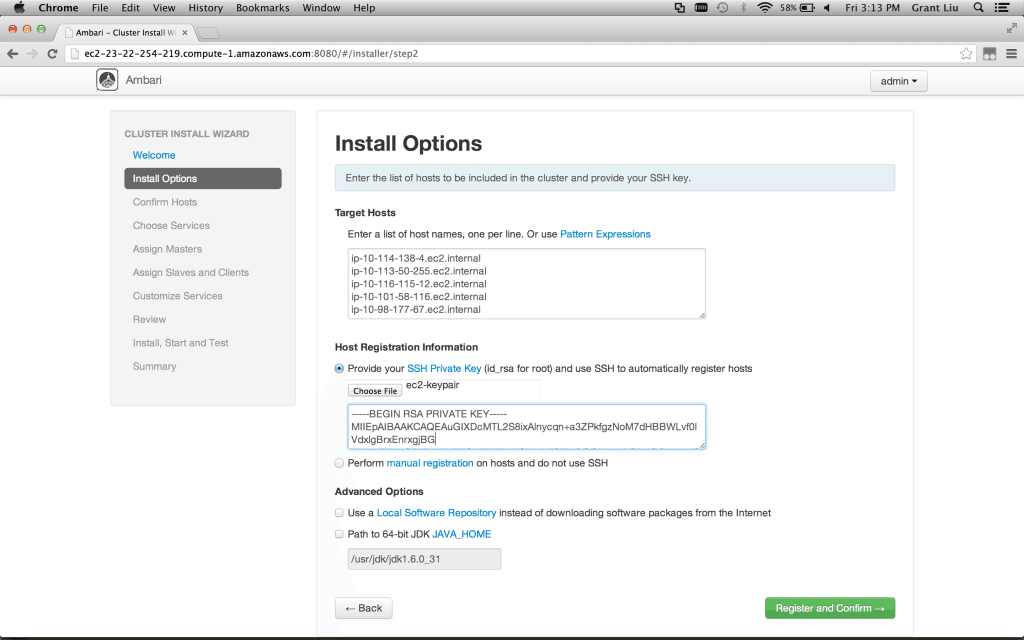
Install Options::Target Hosts – on each line enter the fully qualified hostnames as below (do not add our ambarimaster to the list):
hdpmaster1.hdp.hadoophdpmaster2.hdp.hadoophdpslave1.hdp.hadoophdpslave2.hdp.hadoophdpslave3.hdp.hadoop
Install Options::Host Registration Information – Find the id_rsa (private key) file you downloaded from ambarimaster when you were setting up. Click on choose file and select this file.
Install Options::Advanced Options – leave these as default
Click Register and Confirm
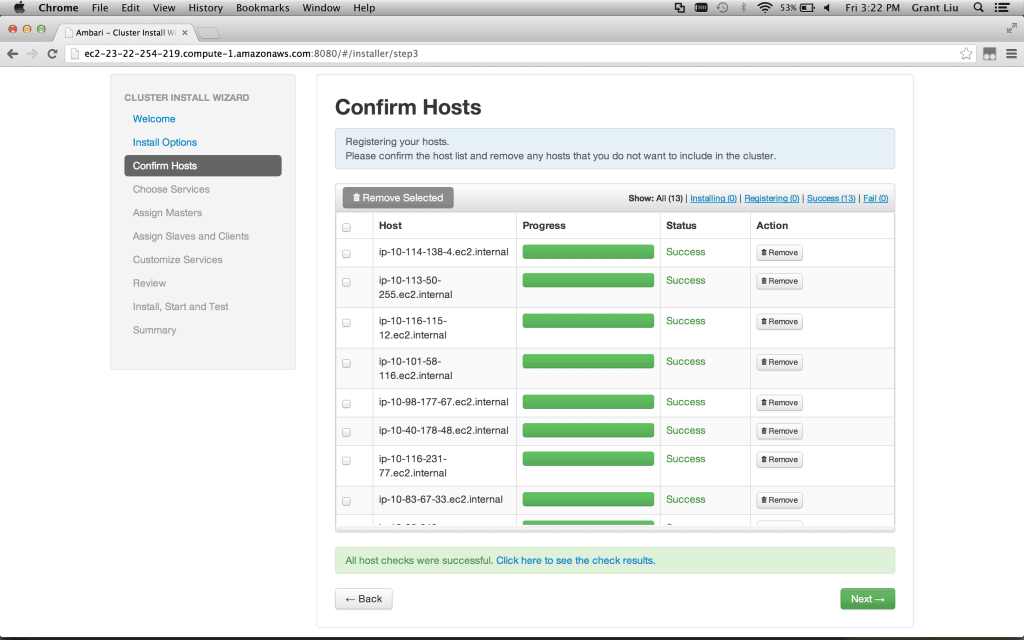
Confirm Hosts – Wait for the ambari agents to be installed and registered on each of your nodes and click next when all have been marked success. Note that you can always add nodes at a later time, but make sure you have your two masters and at least 1 slave.
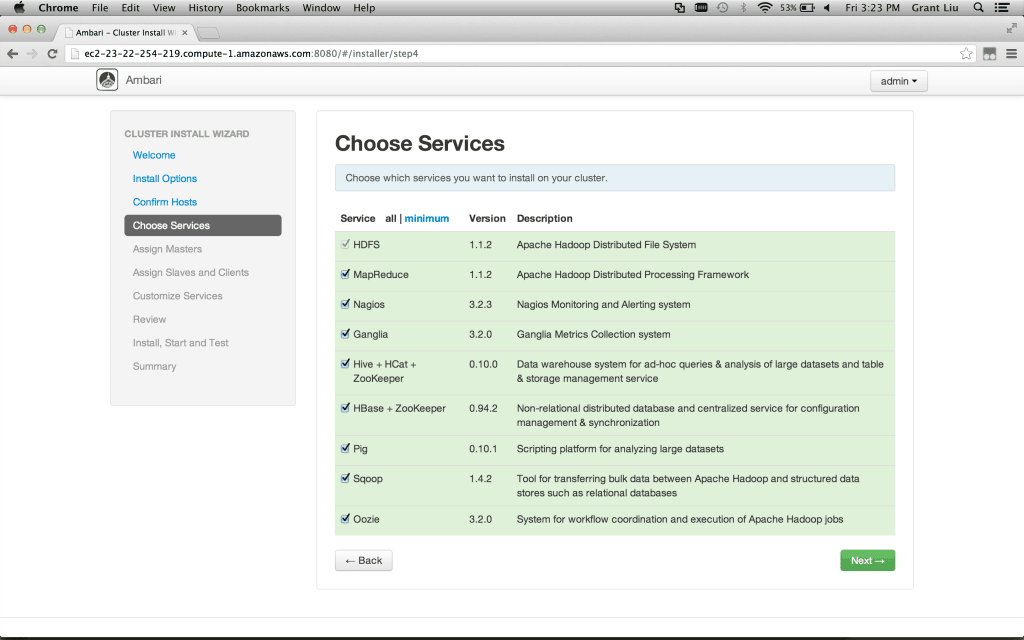
Choose Services – By default all services are selected. Note that you cannot go back and reinstall services later in this version of Ambari so choose what you want now.
Assign Masters – Likely the default is fine, but see below for a good setup. Note that one of the slaves will need to be a ZooKeeper instance to have an odd number for quorum.
hdpmaster1: NameNode, NagiosServer, GangliaCollector, HBaseMaster, ZooKeeper
hdpmaster2: SNameNode, JobTracker, HiveServer2, HiveMetastore, WebHCatServer, OozieServer, ZooKeeper
hdpslave1: ZooKeeper
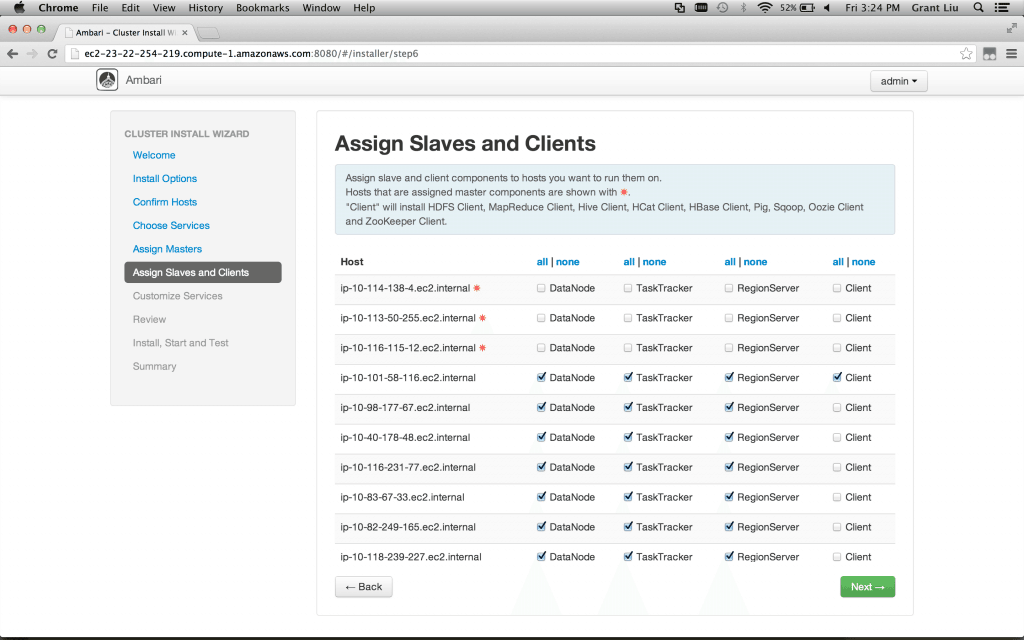
Assign Slaves and Clients – For a demo cluster it is fine to have all of the boxes run datanode, tasktracker, regionserver, and client libraries. If you want to expand this cluster with many more slave nodes then I would suggest only running the datanode, tasktracker, and regionserver roles to the hdpslave nodes. The clients can be installed where you like but be sure at least one or two boxes have a client role. Click Next after you are done.
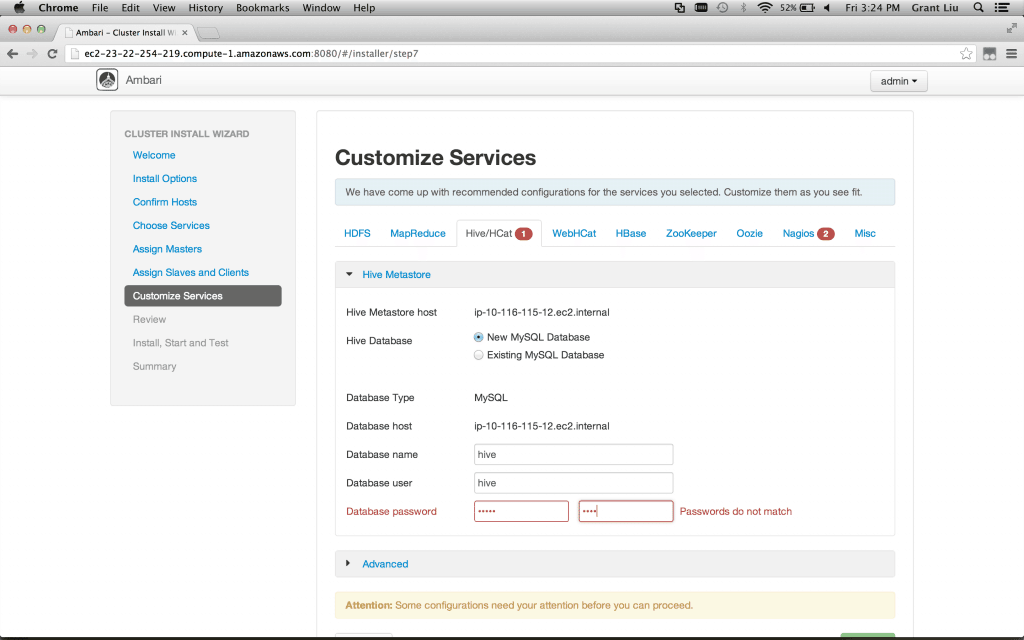
Customize Services – You will note that two services have red markers next to their name: Hive/HCat and Nagios.
Select Hive/HCat and choose your password for hive user on the MySQL database (this stores metadata only); remember the password.
Select Nagios and choose your admin password. Setup your Hadoop admin email to your email (or the email of someone you don’t like very much) and you can experience Hadoop alerts from your cluster! Wow.
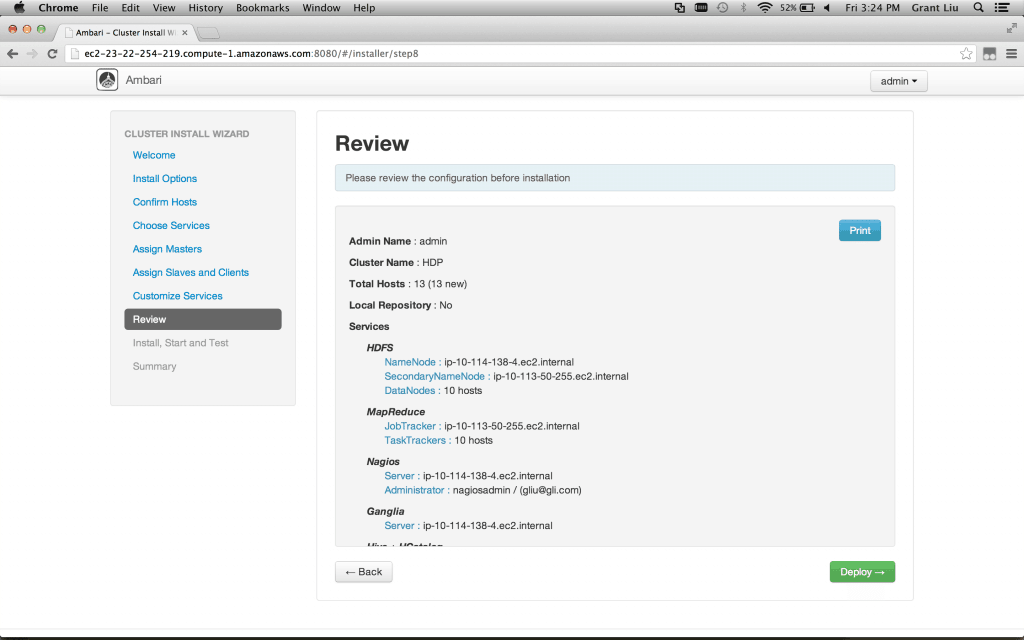
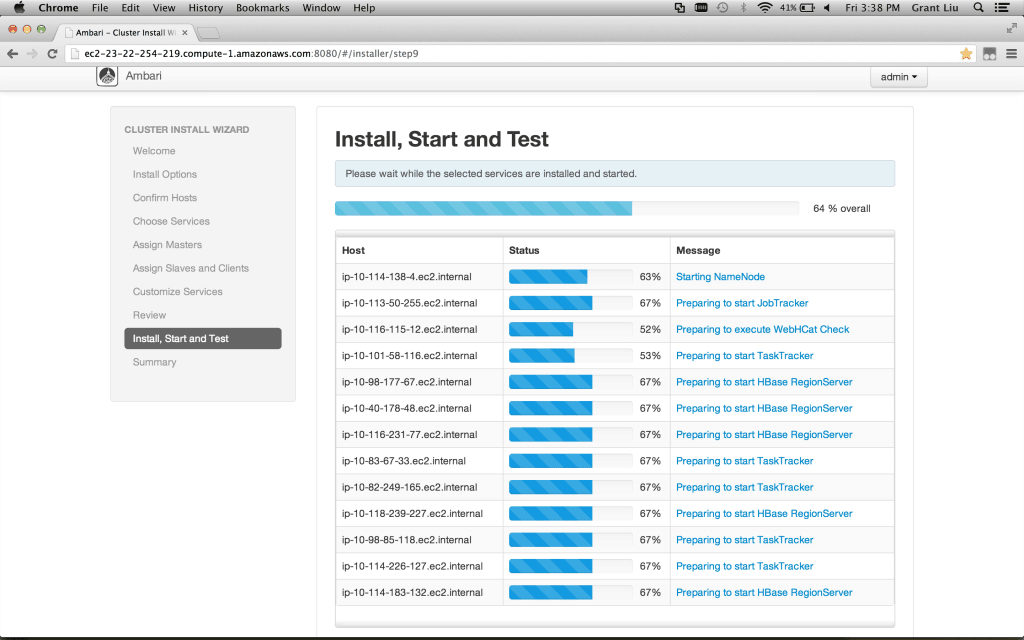
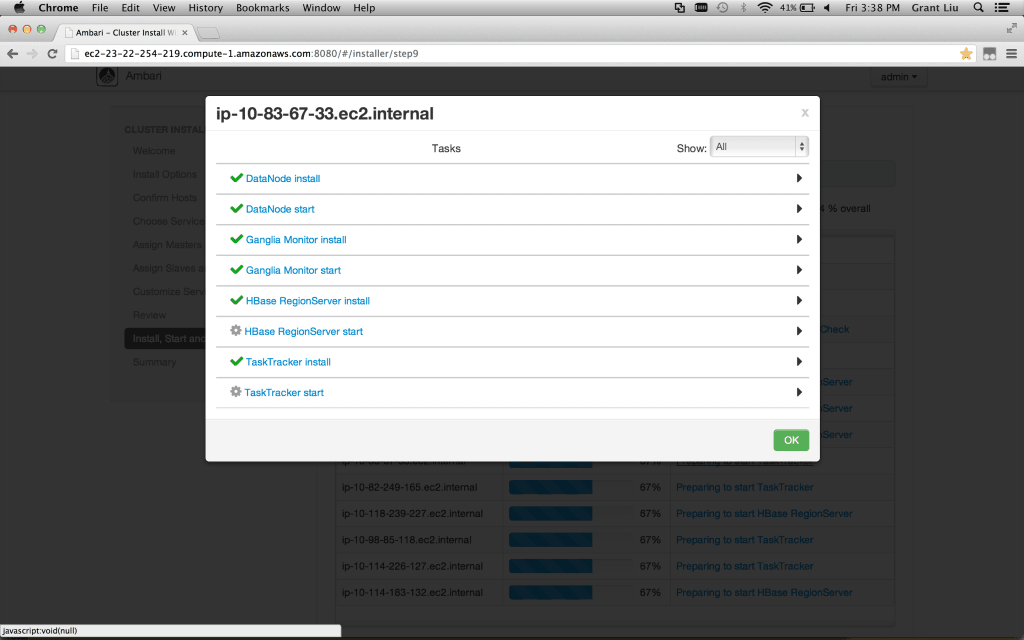
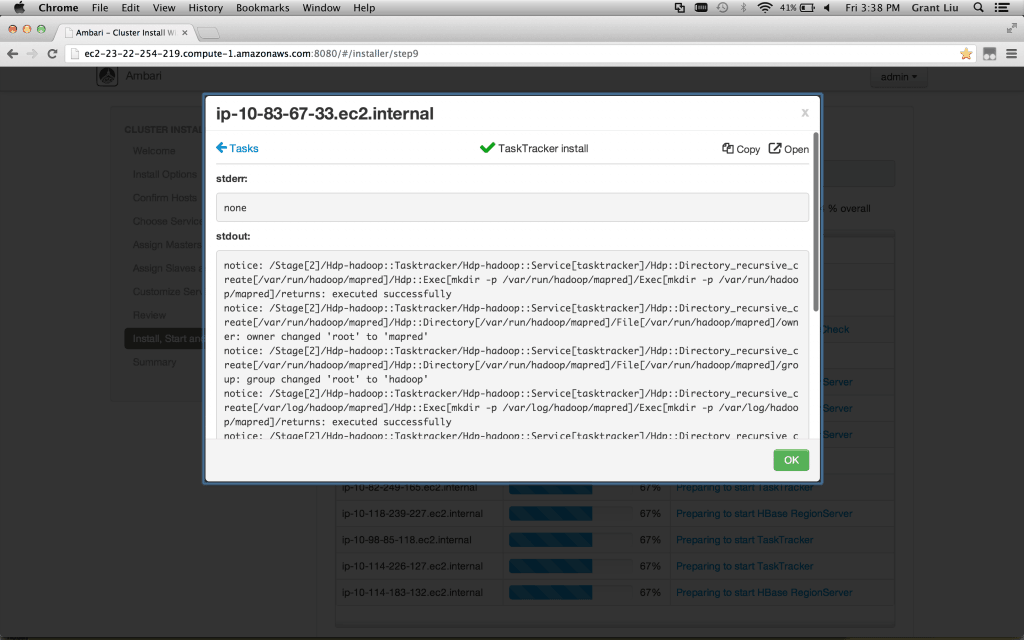
Review – Take note of the Print command in the top corner. I usually save this to a pdf. Then click Deploy. Get a coffee.
Note: you may need to refresh the web page if the installer appears stuck (this happens very occasionally depending on various browser/network situations)
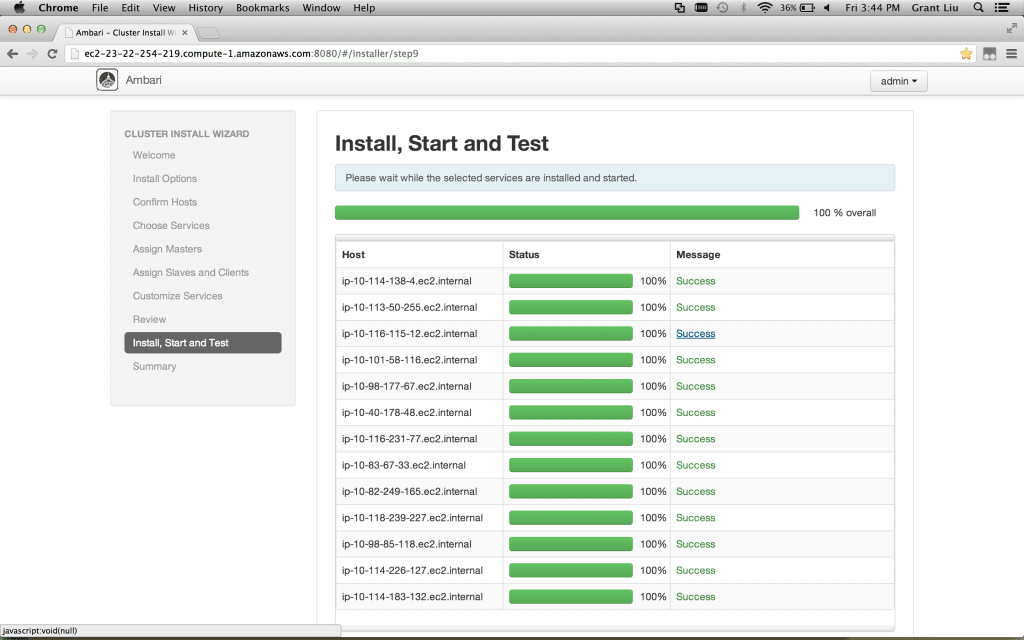
Verify 100% installed and click Next
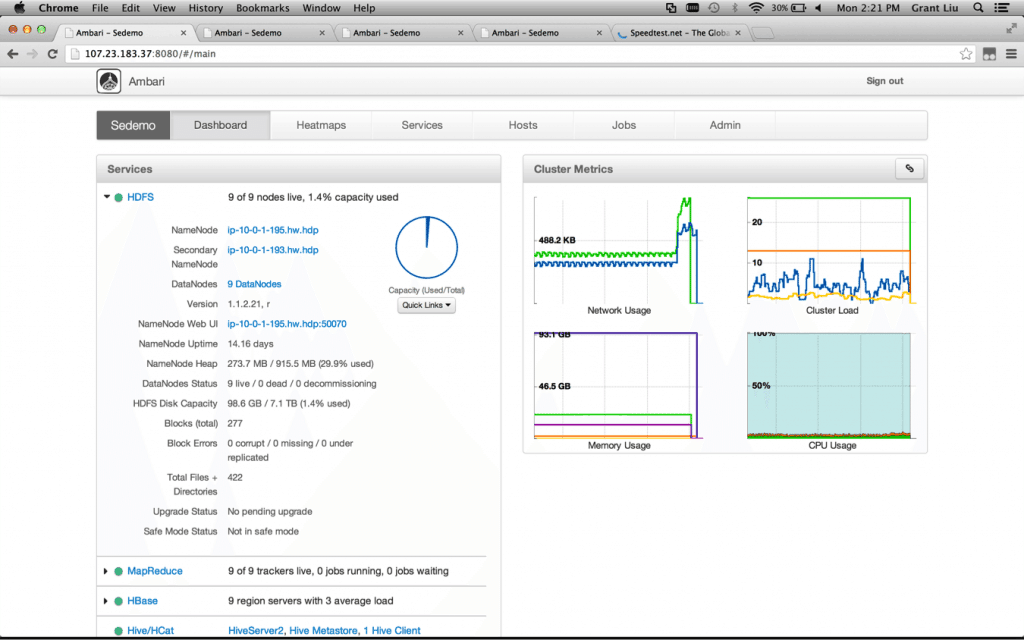
Summary – You should see that all of the Master services were installed successfully and none should have failed. Click Complete.
At this point the Ambari installation and the HDP Cluster is complete so you should see the Ambari Dashboard.
![]()
You can leave your cluster running as long as you want but be warned that the instances and volumes will cost you on AWS. To ensure that you will not be charged you can terminate (not just stop) your instances and delete your volumes in AWS. I encourage you to keep them for a a week or so as you decide how to setup your actual Hadoop PoC cluster (be it on actual hardware, Virtual Machines, or another cloud solution). The instances you created will be handy for reference as you install your next cluster and generally are low cost. Consult AWS documentation for details on management and pricing. Please look into Rackspace as well.
Relevant Links
HDP Documentation:
http://docs.hortonworks.com/
AWS Instructions for using Putty with Linux EC2 instances:
http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/putty.html
AWS Discussion of Static IPs:
https://forums.aws.amazon.com/thread.jspa?threadID=71177
Adding a new drive to RHEL 6 (Relevant for adding volumes for Datanode storage):
http://www.techotopia.com/index.php/Adding_a_New_Disk_Drive_to_an_RHEL_6_System
Toronto Hadoop User Group:
http://www.meetup.com/TorontoHUG/
Some more details on this process with Amazon EC2 and Cygwin:
http://pthakkar.com/2013/03/installing-hadoop-apache-ambari-amazon-ec2/
The post HOWTO: Ambari on EC2 appeared first on Hortonworks.